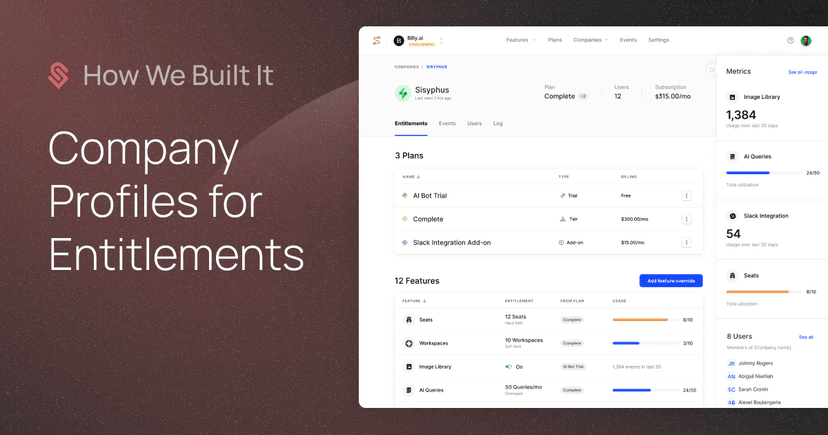
How we built company profiles to support entitlements
Jasdeep Garcha
Ben Papillon
·
10/04/2024
In the post below, we’ll explore some of the design decisions we made while building centralized profiles to support feature flagging for an entitlement use case.
Entitlements are the relationships between what a customer is sold and what they actually get access to in a product. A simple example of this is a Free tier with 1 seat and a Pro tier with 5. If the customer buys the Pro tier, they are entitled access to 5 seats.
We’ll cover the following below:
Why we decided to do this (rather than alternatives)
The challenges of building towards our requirements
The design choices we made
Future improvements
One of the unique aspects of building feature flags for an entitlement use case is how much context is required to support pricing and packaging policy. There is, of course, metering, but also attribute-based targeting and decisioning such as feature exceptions, beta groups, where a customer bought from (geography, channel), where they are in the sales process, etc.
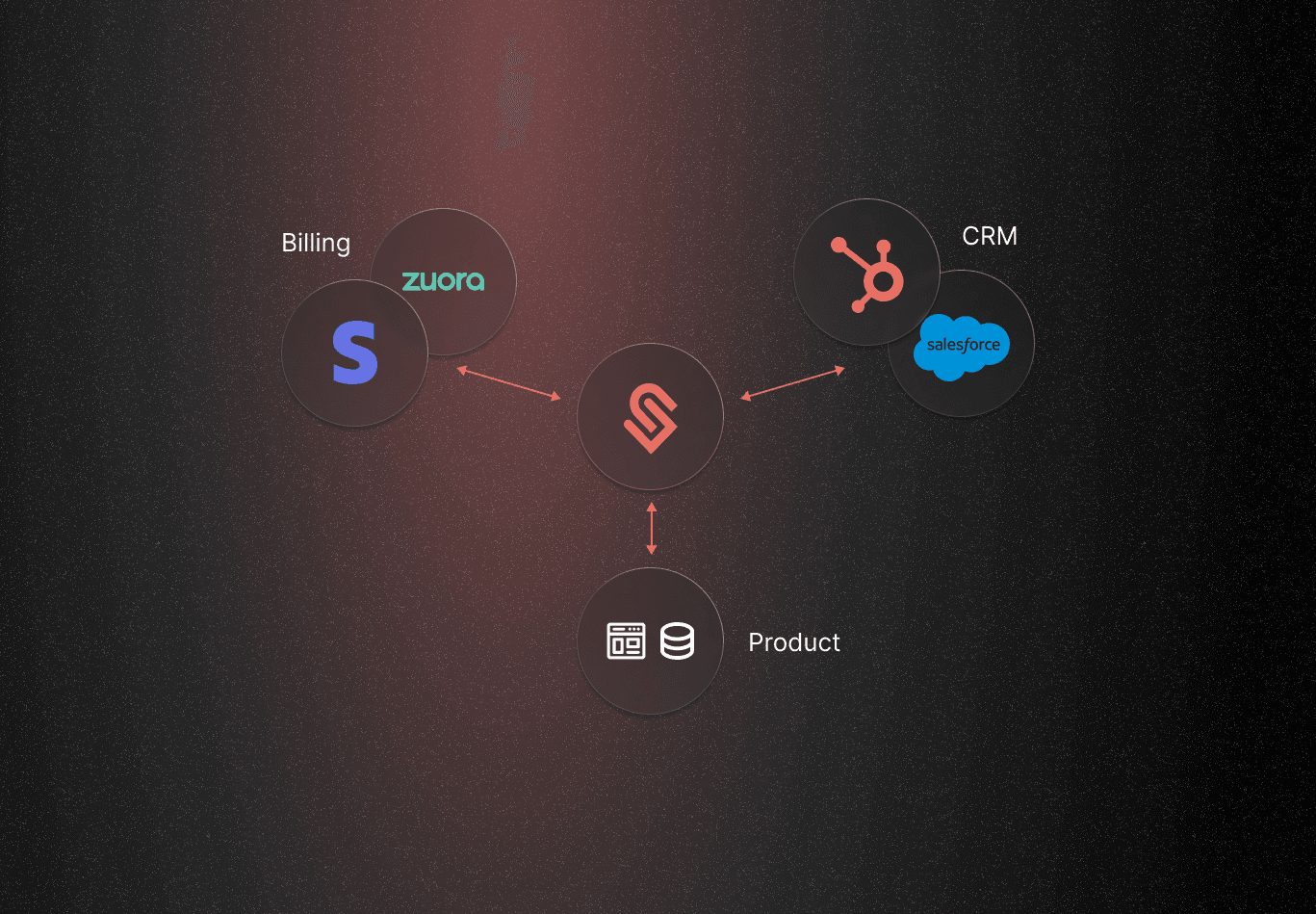
Traditionally, teams tend to bite the bullet and store all the necessary context themselves either in tables, config files, or just hard coded logic. This gets messy if done ad hoc.
When we started building Schematic, one of the first things we built were centralized user and company profiles. Doing so allowed us to better organize data from a variety of sources and inform flag evaluation and pricing and packaging policies without additional context, and, eventually, dynamically populate UI components for pre-baked purchasing experiences.
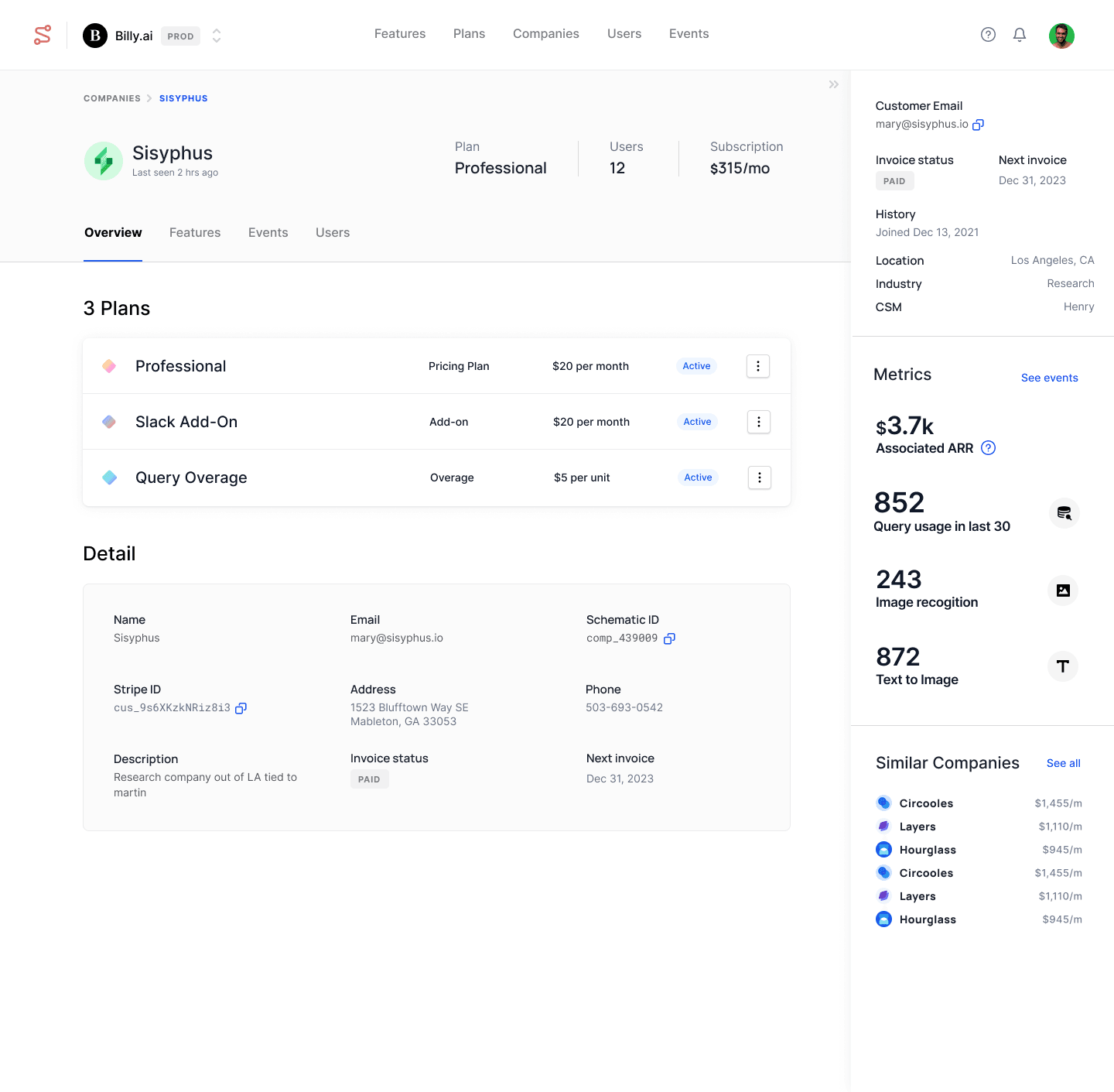
This is a different tact from most products on the market today that offer feature flagging capabilities. In many cases, those products don’t need to store context because they put the onus on the user to send in context at the time of evaluation.
Which begs the question: Why design our system differently than best in class feature management tools?
From the outset, we set out to abstract pricing and packaging logic from applications. Core to our belief is that although applications should respond to business state, it’s not the responsibility of applications to retrieve, hold, and maintain that type of state. It overloads software development, and it makes maintainability really difficult.
With that in mind, we had three core requirements when architecting the system:
Unified Access to Billing, Account, and Usage Data: We wanted users to be able to access all relevant information in one place both for reference, to use for flag targeting, assigning entitlements, and to build custom solutions on top of. This required integration with third-party services to pull in billing and usage data and robust APIs to handle frequent updates.
Avoiding Persistent IDs: We wanted to, of course, have a unique ID on a per entity basis, but we also wanted to avoid introducing yet another persistent ID that would have to be referenced across all of a customer’s existing systems and their application. This was slightly preferential, but allowed users to use multiple keys that already existed to identify a company or user in the system, depending on where data was being requested or retrieved.
Context-Aware Rule Evaluation: We wanted to support rule evaluation and segmentation across several contexts, such as:
Metering and Usage Data: Handling data such as how many API calls or credits a user consumes.
Based on Arbitrary Trait Values: Incorporating custom attributes like region, method of purchase, industry, etc.
Driven by Association: Defining relationships between objects from both first-party data and third-party sources (e.g. what plan a company might be subscribed to), allowing implicit rules to act based on those dependencies between users, accounts, or external entities.
The user could, of course, supply information to us at the time of flag evaluation, however that would require maintaining a data pipeline and aggregation logic (in the case of metering) and building deep integrations into third party systems (in cases where third party context is necessary), among other requirements.
Building a system that operates in this way and relying on stored context for flag evaluation is challenging because it’s inherently distributed and must be performant. Here are some of the difficulties we faced:
Latency & Resolution Time: Since the system ultimately powers real-time flag evaluations for pricing and packaging policies in applications, low latency was critical both in updating context and delivering a result.
Race Conditions: Frequent context updates (usage, attributes, associations) and parallel processes created opportunities for race conditions, where the system might try to act on outdated or conflicting information.
Idempotency: We needed to ensure that repeated requests or updates wouldn’t result in inconsistent or erroneous states — especially important given that multiple systems would be sending data at unpredictable times.
Privacy Concerns: With personal data sometimes involved, the system needed to be built with privacy-first, particularly to ensure compliance with SOC 2 and GDPR requirements.
Below is a high level design of how an entitlement evaluation works in the system.
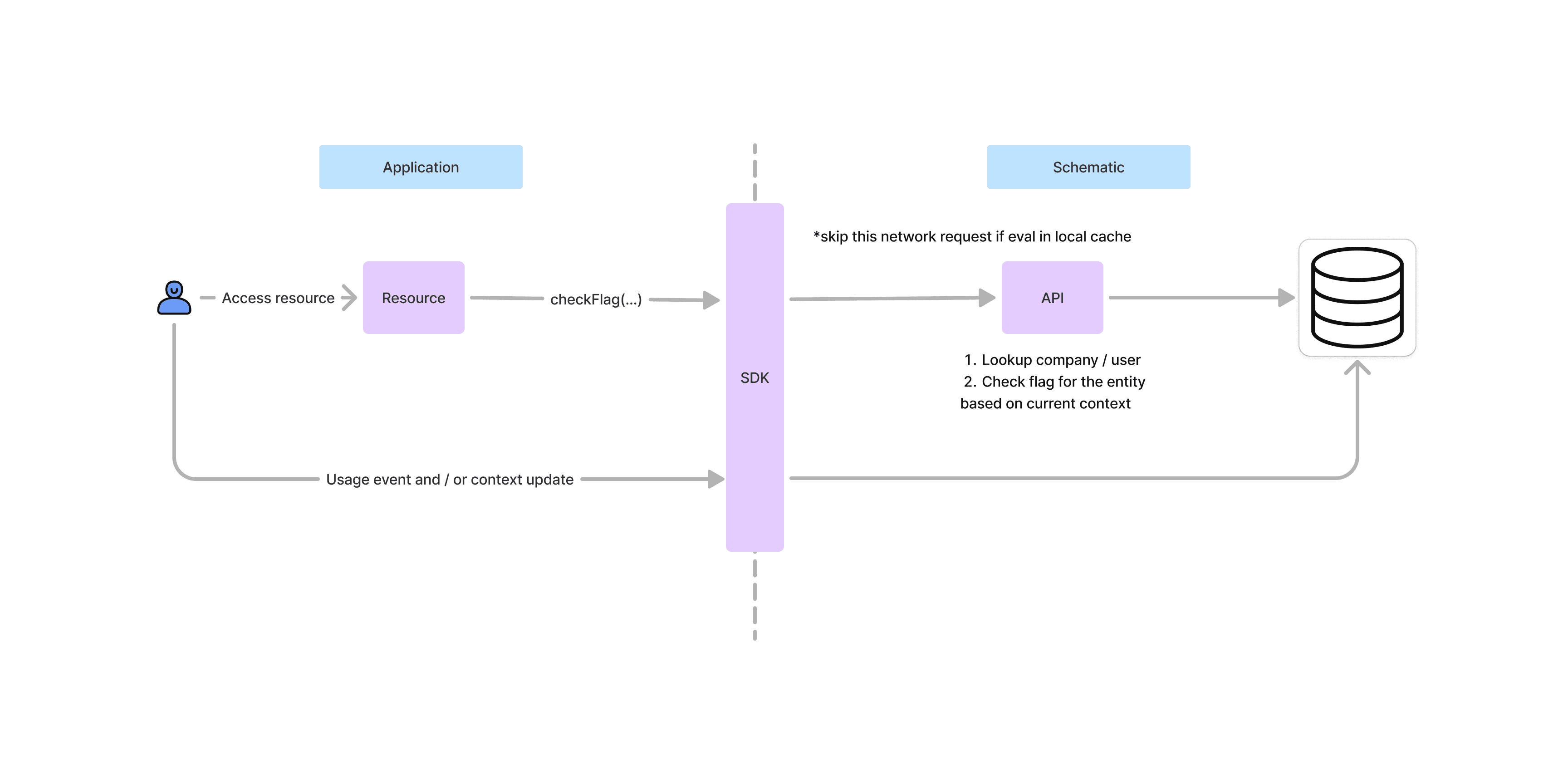
Here’s how we addressed the above challenges in those transactions with specific design decisions. While we’ve reached a level of maturity in some buckets, there’s a ways to go in others that we’re already planning for.
We figured the critical latency requirement would be the time it took us to return a flag evaluation, which is the most performant part of our architecture (< 150ms). Flag values are almost never calculated on the fly, but instead continuously updated and stored in a Redis cache. Moreover, we implemented in-memory caching of flag values in our SDKs so that frequent network requests would not be required from clients.
There are drawbacks to that, though (and future areas of improvement).
When we receive updated context about a company or user, we immediately update company and user profiles; however, downstream flag evaluation updates are an asynchronous process. We made this choice because a change in context could impact many rules and policies, and we didn’t want to tie all of that together in a single synchronous process.
The result is that, today, the system is most relevant for applications that can tolerate some data staleness.
The next major investment along these lines is aimed at high performance use cases that cannot tolerate staleness. This will push flag rules and entitlement policy client-side, so they can be evaluated independently.
We support multiple third party integrations and expect to receive frequent context updates from a user’s application in the form of trait updates (via our API) and usage events (via our event capture pipeline). This means a single entity (company or user) can be operated on simultaneously across a variety of contexts.
To mitigate the risk of race conditions we implemented a number of measures:
For API transactions, we perform all actions atomically, so if a request comes in while another one is in process, we either queue it or fail the request so it can be retried.
For eventing, we invested in buffering to temporarily store incoming data, allowing the system to process updates in a controlled, sequential manner.
For data from third party integrations, we store data in unique objects (e.g. subscriptions) and associate it with profiles asynchronously.
We use a combination of entity keys and idempotent keys to ensure that requests are performed on the right entity and that repeat actions do not alter outcomes in unintended ways, respectively.
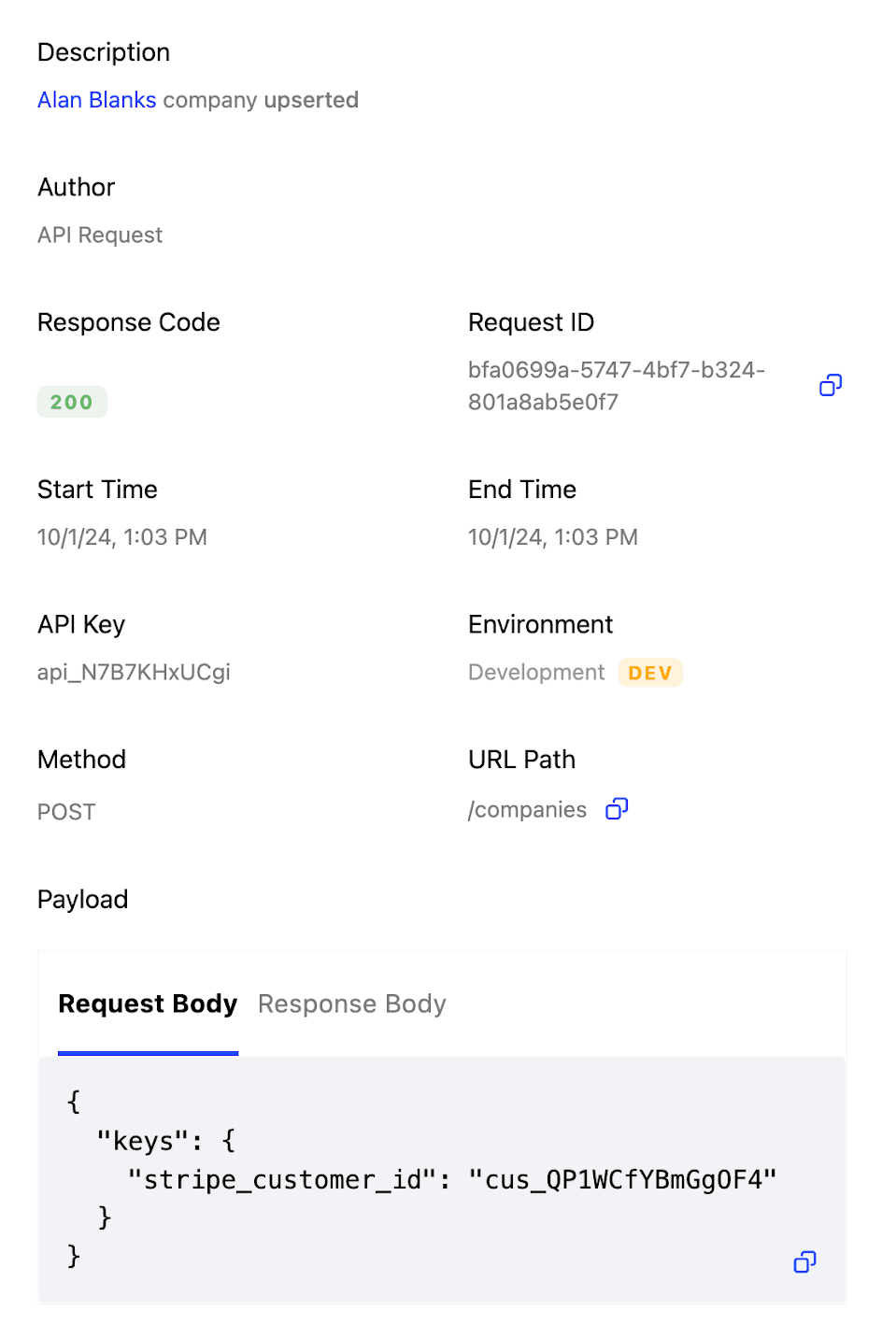
Company and user updates are performed as upserts (update or insert operations) to allow us to handle data changes in a way that preserve consistency.
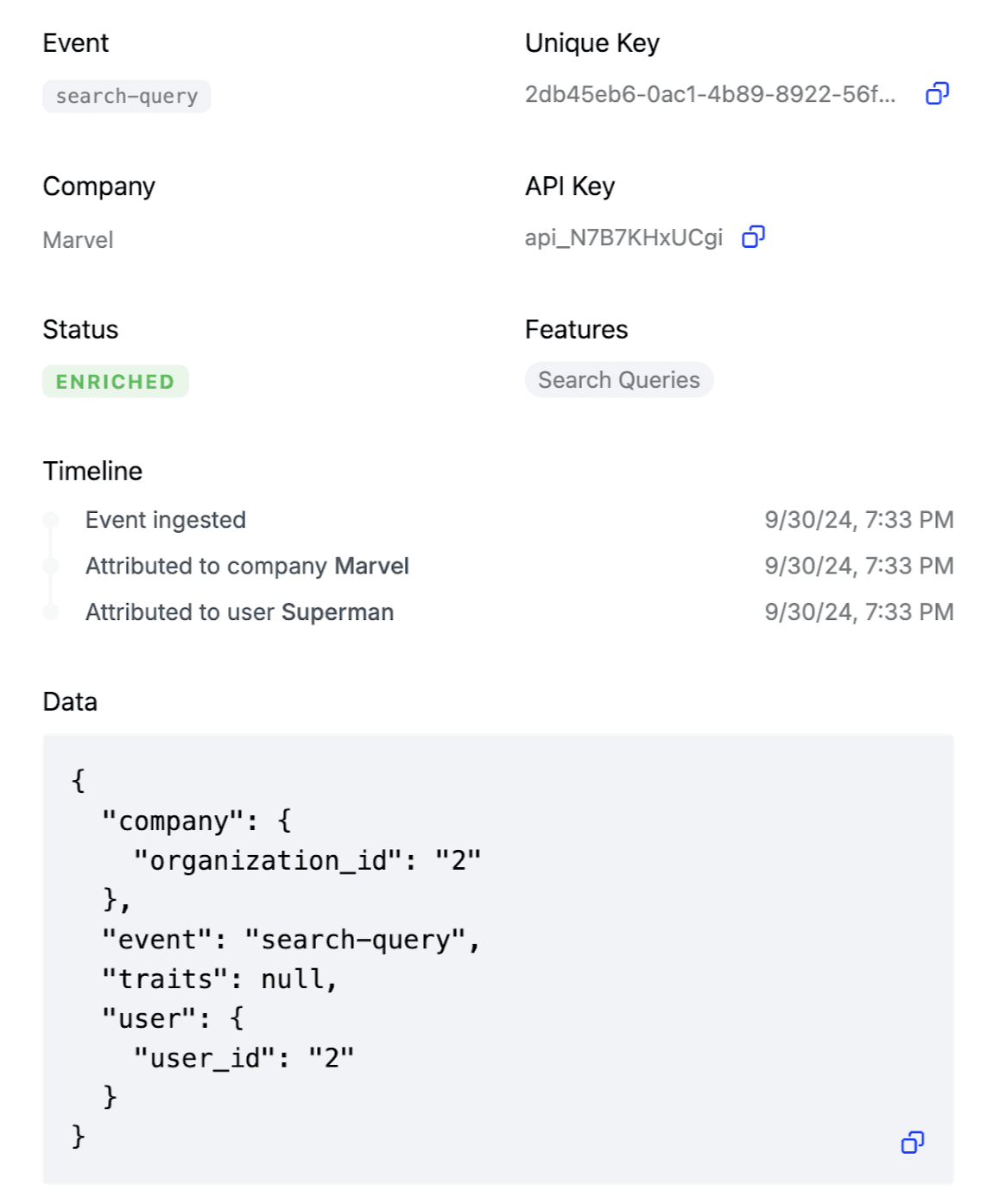
Each usage event also has a unique key and a timestamp to avoid duplication and ensure sequential ordering.
When we began building, we simultaneously went through a SOC 2 audit so our systems would be designed to be SOC 2 compliant by default. While we were drawn to use services like Fly.io initially for their ease of deployment, we quickly transitioned to AWS so maintaining compliance was much more straightforward.
Moreover, given the possibility of personal data stored in our system, we implemented a GDPR delete endpoint to permanently remove company and user entities, as well as all associated data.
The only alternative we entertained was not storing context at all, given that's the status quo for other tools that are built for more ops-oriented use cases.
As we highlighted a bit above, we didn’t feel like this was a viable alternative for entitlements use cases. Going that route would defeat the purpose of a managed solution entirely because we’d be asking the user to store data from third party systems like Salesforce and to maintain their own event pipeline with homegrown infrastructure.
Not only is this a lot of work to build and maintain over time, we believe it’s just not core value to do for most.
There are a number of improvements we can make to this system to better mitigate the highlighted challenges and to expand the utility to more situations.
We’ve built the system to be aware of current context rather than hypothetical context. This works well for entitlements that are either on or off, or are consumed incrementally. In those situations, the question is relatively straightforward: “Does the company have access based on their current state?”
However, this design runs into challenges when an entitlement might be consumed variably or in a batched manner and has a corresponding limit. For instance, the ability to submit a batch of API requests at once, or the ability to upload a batched set of requests all at once. Even if a company is under an entitled limit, if a company attempts to perform a batched action that will push them over that limit, the action should be rejected. In those situations, the question becomes: “Does the company have the ability to submit X number of requests?”
To support such scenarios, the system design must accept some data at the time of evaluation so the system is aware of what is being attempted rather than rely solely on profile data. Here’s an example that functionally allows the user to diff the utilization metric at time of evaluation to ask the hypothetical question above.
schematic.checkFlag('can-publish-pages', { used_pages: { diff: 3 } });We built the system today for situations where there is some tolerance for data staleness. However, there are plenty of situations where high performance is both desired and necessary. For example, products that are consumption-based with hard limits require evaluation to take into account almost real-time context.
We’re planning on supporting those scenarios by pushing more of our data and logic client side to avoid network requests and latency due to asynchronous processing. That would manifest itself in streaming profile data and caching rules, not simply flag evaluations, client-side so rules can be processed on the client with up-to-date context.
So far, we’ve served over 500K entitlement evaluations powered by centralized profiles across a number of production instances. Those use cases run the gamut from company-specific exceptions to usage-based limits and configured features.
The aggregated data we gather from rules that are set up in our system, as well as data from external sources, forms a complete company profile, which not only helps in evaluating flags that power entitlements but it also allows us to seed UI elements for pricing and packaging views in the application.
By pulling together all this information, we are able to present a single source of truth for billing, account, and usage data — something that, in our experience, is quite difficult to build and maintain.
Ultimately, this allows businesses to create more dynamic, responsive pricing and packaging that can adapt to complex customer needs very quickly, and answer unique questions about customer context.